EVM 字节码的默克尔化
- Unitimes
- 发布于 2020-04-26 21:30
- 阅读 1010
如何将合约代码分割成块并默克尔化达到节约了40-60% 的代码传输量。
摘要: 无状态客户端需要将区块中调用的智能合约代码作为区块见证的一部分进行发送。合约代码是导致无状态区块带宽开销的第二大因素。代码默克尔化被认为有助于降低该开销。本文详细解释了我们如何将合约代码分割成块,默克尔化这些块(笔者注:指的是让这些块组成一棵默克尔树)并仅传输交易执行所必须的块。根据对最近主网区块所做的实验,我们可以发现该方法总计节约了40-60% 的代码传输量。
无状态区块很大
虽然未被深入研究过,代码默克尔化这个想法由来已久,其主要被用于代码解耦。然而,它最近因不同用途而重获新生,即减小无状态客户端的带宽需求 。如果你想知道无状态客户端背后的动机是什么,我建议你看看最近这篇概要或者 Alexey Akhunov 的文章(文中发布了其实验数据)。我不会在本文深入模型细节,但为了完整起见,我提供了相关细节的摘要(如果你熟悉的话,你可以直接跳到下一段)。
在无状态模型下,(至少有些)节点不需要存储状态,并依赖其它节点(如矿工)在区块中打包所有必要状态(包括合约代码)及证明这些状态有效性的默克尔证明。这意味着和原来相比大得多的网络带宽。Alexey Akhunov 与 turbo-geth 团队一直在做测量历史主网区块的区块见证大小的实验。下面是最近 50,000 个区块的测量结果。红线跟踪在一个无状态区块中需要发送的合约代码量,其为区块见证大小的第二大来源。如果以太坊从当前的十六进制 trie 树迁移到二进制 trie 树的话,这些见证中的哈希部分将会缩减约3倍,从而使得合约代码成为见证大小的主要来源。
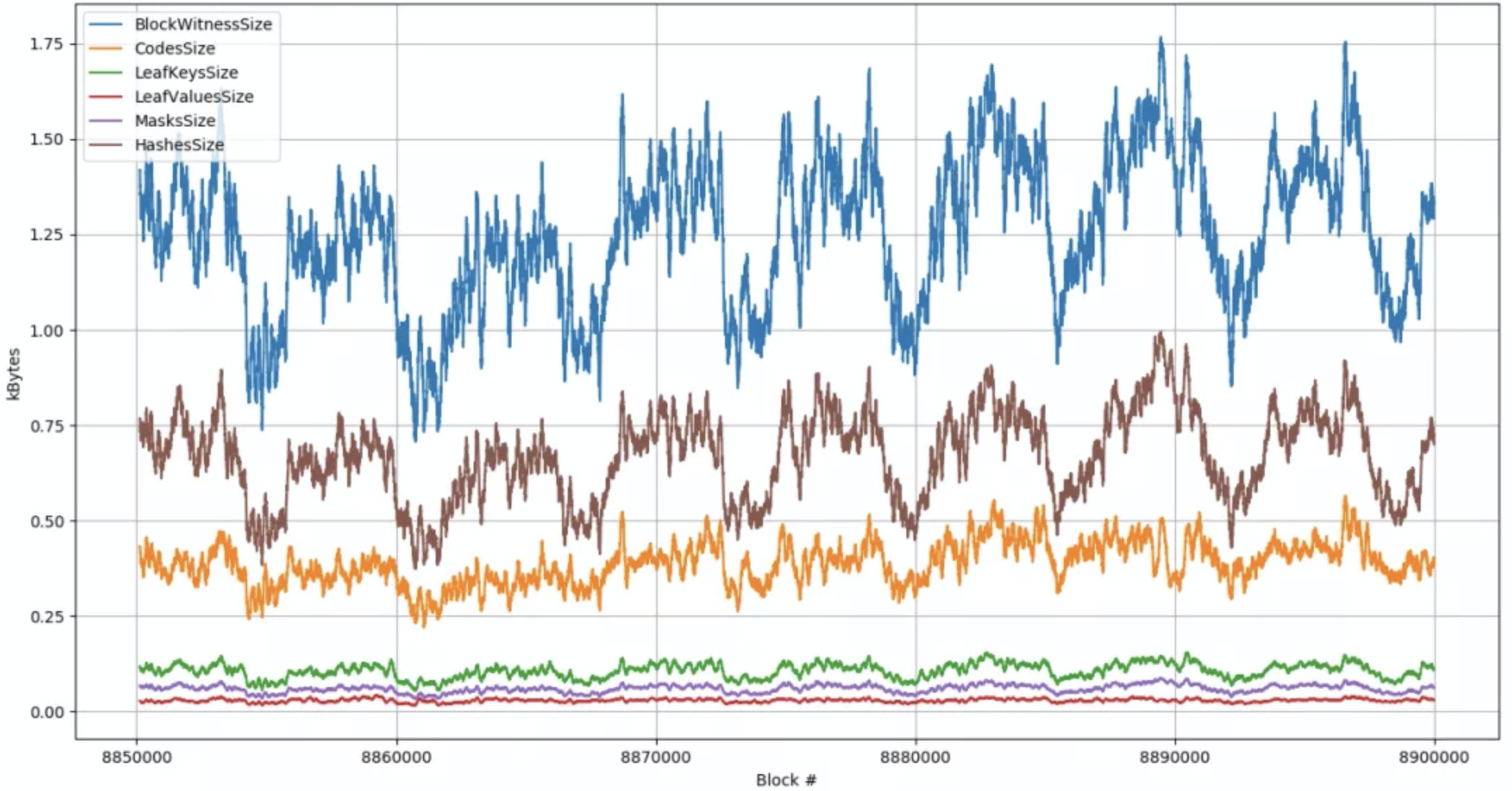
来自github的数据。图表显示了50000个近期主网区块的无状态区块见证组成。这些值是以128个块为窗口的移动平均值。
无需发送完整代码
直观地,我们可以假设一个给定的交易将仅仅触及其调用合约的部分代码(如4个函数中的2个)。因此,我们的目标是把代码分割成块并在区块见证中发送给定交易所必须的块(加上块有效证明)。如果我们的假设是正确的而且交易确实仅使用了小部分合约字节码(剧透:早期数据表明情况确实如此),那么区块见证中的合约代码部分会显著减少。
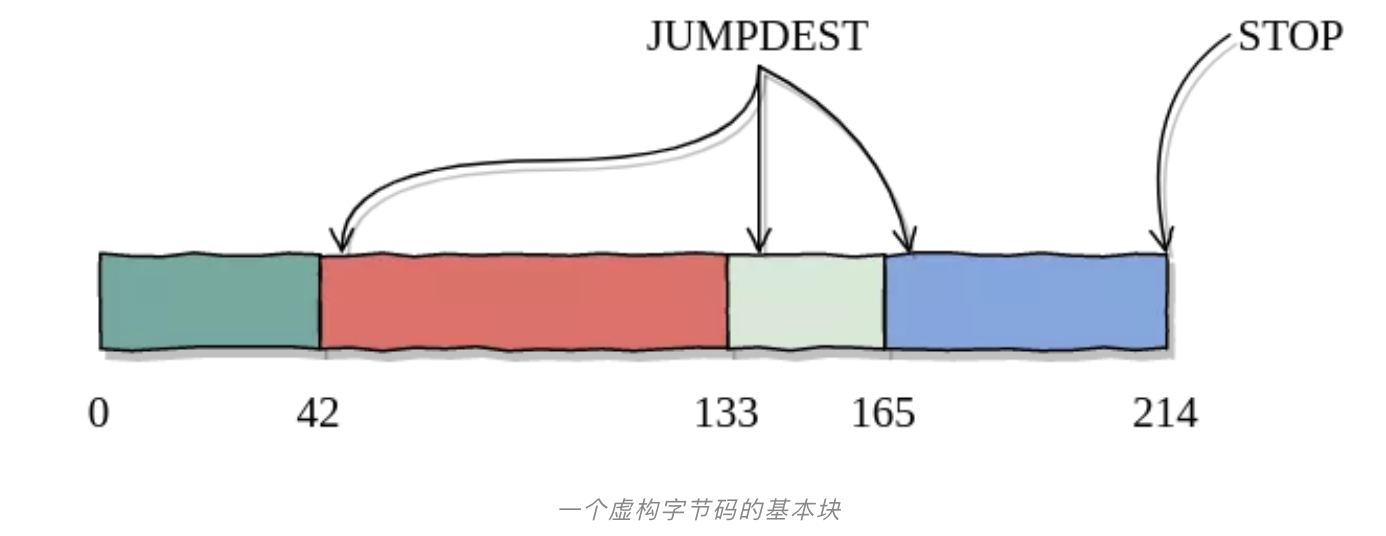
为了确切地了解其原理,让我们想象一个正在部署的新合约。我们扫描合约代码并识别出基本块(见算法)(笔者注,基本块可以理解为按序执行的一段代码片段)。注意,客户端仅需为JUMPDEST分析作一次代码扫描,因此不会引入很高的开销。这些基本块有两个特征:
-
每个基本块要么从索引0开始,要么从JUMPDEST开始。这是为了让无状态客户端能够安全地进行JUMPDEST分析(稍后将更为详细地介绍)。
-
每个基本块不会改变控制流(如没有JUMP)。因此,我们可以确定,一旦我们开始执行一个基本块,要么它将运行到最后,要么它将耗尽Gas。我们假定这方案会更为高效,但仍未测试其替代方案来作对比。
为了提高效率,相邻的基本块将会合并直到每个基本块的最小长度为128字节(这是一个可配置的参数)。然后将它们插入trie树中,使用其第一个字节的索引作为键。客户端最终将此trie树的根存储在记录该合约的新创建的账户中。如下所示,代码trie树实际上成为了状态trie树的子树(类似于存储trie树)。
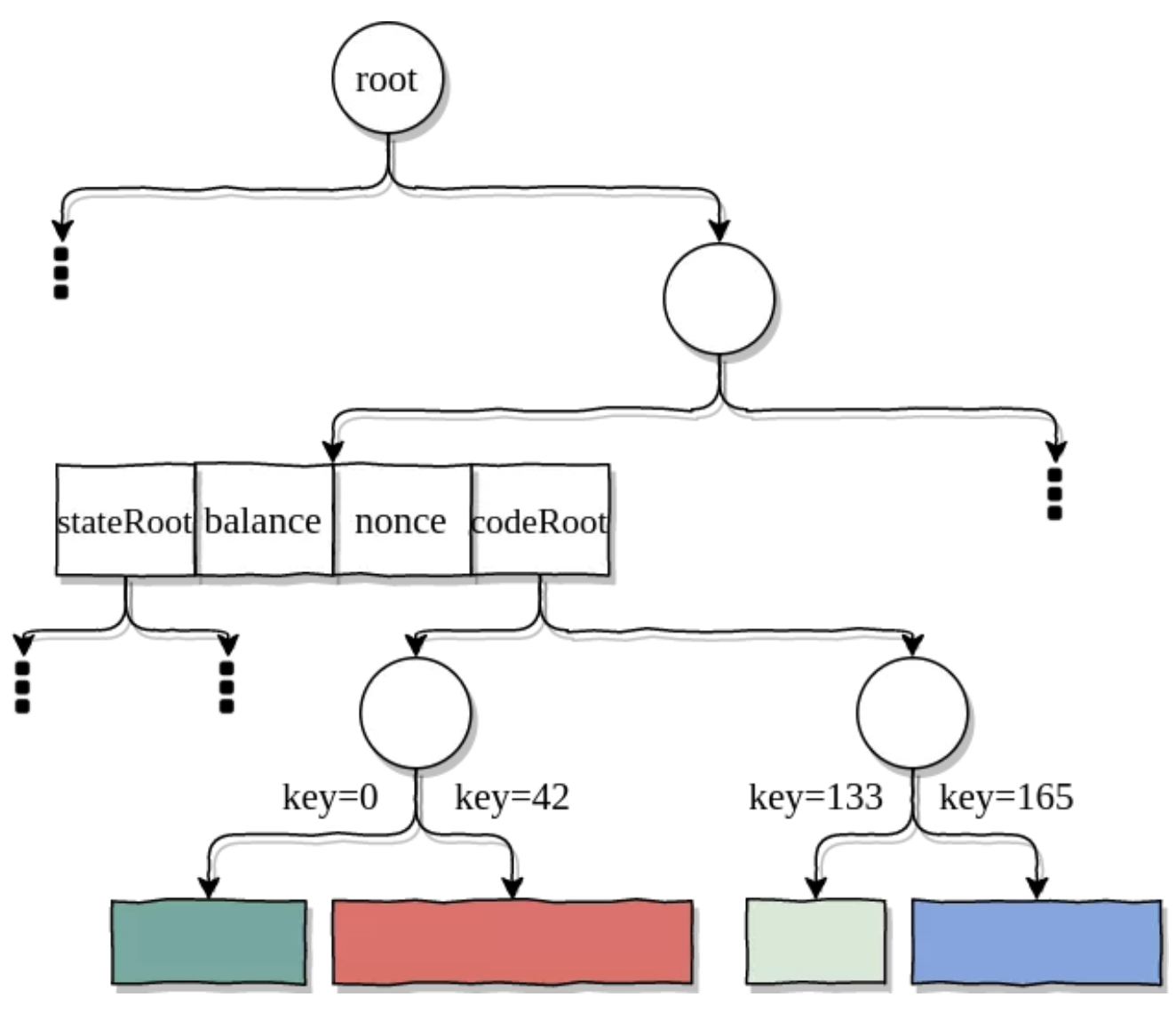
默克尔化的合约代码成为了状态trie树的子树。为了简化图表,我使用了二进制trie树(而不是以太坊中使用的MPT树)。路径和键值也不太准确。
让我们通过提交调用合约的交易来进行测试。矿工执行交易并标记在执行过程中触及的块(在本例中为块1和块3)。当发布区块时,矿工会纳入合约账户状态证明和触及代码块的turbo证明。
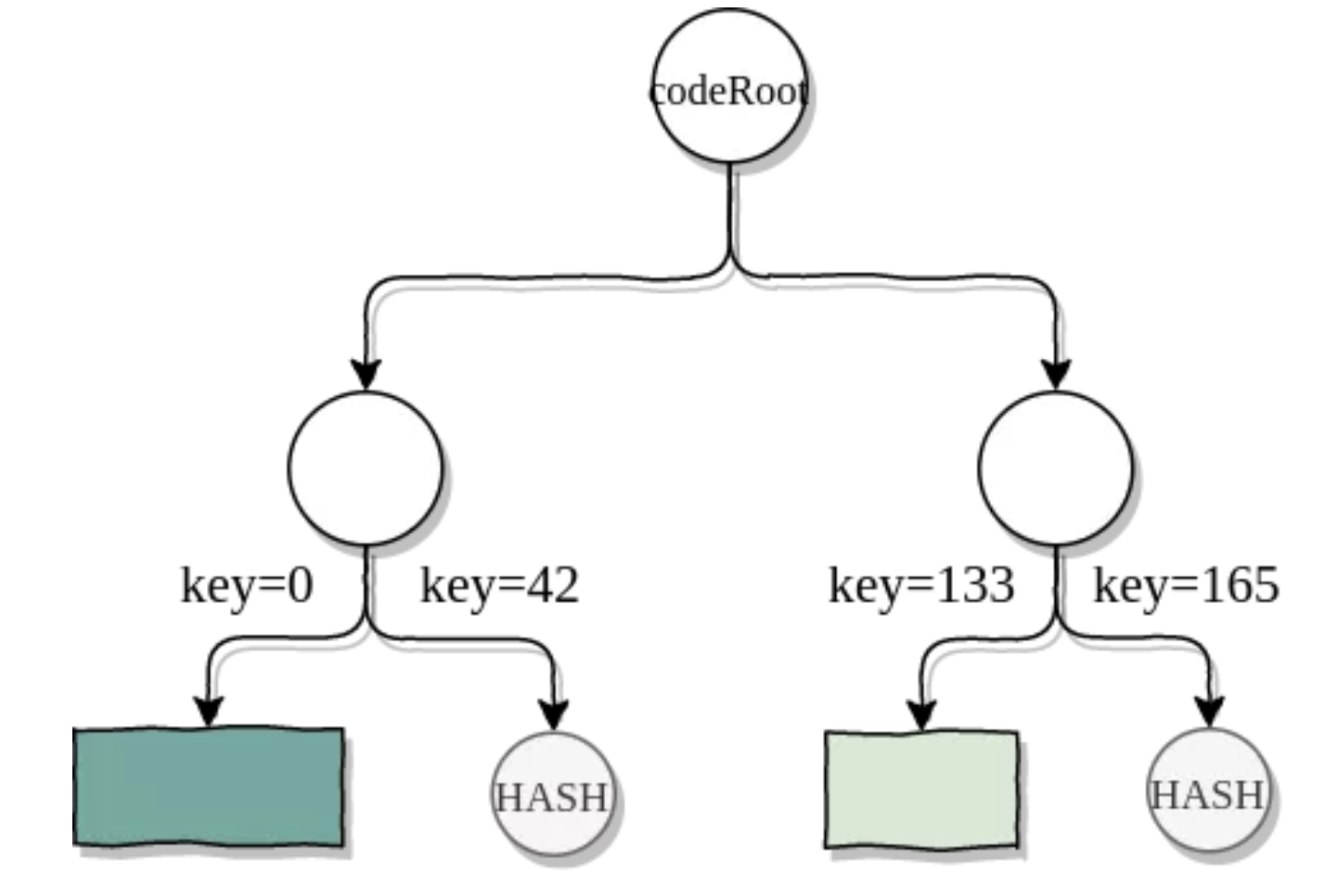
触及块与验证代码根所需的哈希作为turbo证明进行传输
收到该区块后,无状态客户端可以验证合约是否为状态的一部分以及是否有着正确的属性:余额,nonce值,状态根和代码根。然后,它可以根据代码根去验证代码块及其键值。上述信息足以让客户端从这些块中重构出部分字节码并让其它块留空。值得注意的是,根据我们采用的块分割算法,客户端知道每个块(第一个除外)都以JUMPDEST开始,因而可以安全地执行跳转。
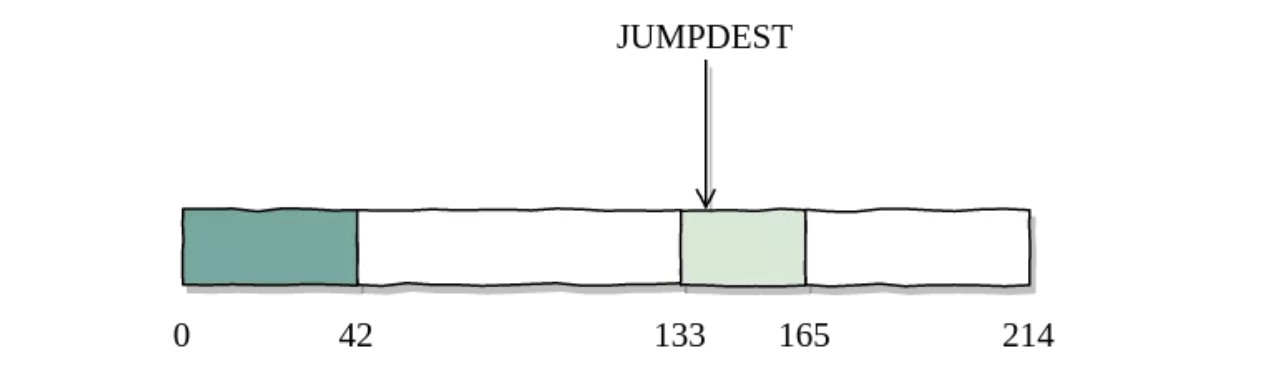
从trubo证明,我们可以重构字节码。给定交易所不需要的块则留空。
实验
为了测试,我们编写了一个原型,其通过Geth的RPC端口抓取主网区块及初始状态。然后,原型在这些区块中运行交易,每当遇到新合约时,把合约分割成块并对触及块进行标记。当区块中的所有交易被处理后,原型会为这些块生成turbo证明。我们在更新后的初始状态(仅仅把合约代码替换为由证明计算得到的重构代码)下重新运行这些交易。为了检查正确定,我们比较了使用的Gas量以及区块的布隆过滤器。对最近的50个区块进行处理,我们可以看到代码量的减少在40%到60%之间。
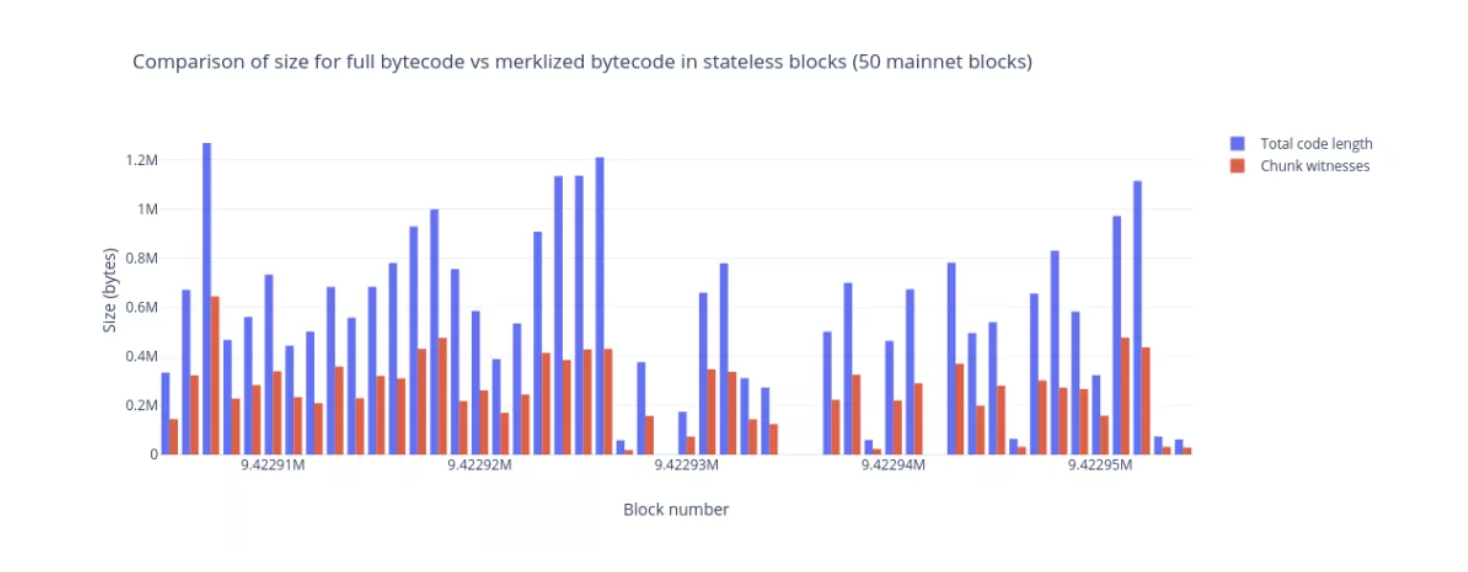
警告:这些数据虽然看上去不错,但请记住,我们需要数万个区块的数据来得出有说服力的结论,而且原型正处于初始阶段,因此很可能有Bug。
何去何从
你可能仍记得,每个块的最小长度是一个可配置的参数(上文把其设为128字节)。修改该参数会对块见证的大小有着两种相反影响。例如减少至32字节,让块的粒度更细,从而减少了需要发送的代码总量。但同时也增加了trie树的深度,最终导致证明所需的哈希数增大。下一步将会对最小块大小的设定进行更彻底的分析,看看是否有一个最为节约空间的值。不管最小块大小的值,从十六进制trie树切换为二进制 trie 树会将证明所需的哈希值减少为原来的1/4(见这里),从而进一步减小块见证的大小。
对于该原型,我们选择将代码分割为一个个基本块,但也存在着其它各种各样的分割算法,有些更为简单,有些更为复杂。最简单的方法是把代码分割为固定大小的块(如每32个字节为一个块)。目前,该方案的唯一问题围绕在 PUSH 数据和 JUMPDEST 分析之上。
以此为基础进行展开:如果我们在任意边界分割字节码,PUSH操作码及未来引入的其它多字节操作码的操作数可能会被接收到块的客户端误以为是JUMPDEST(0x5b)。如下所示,一个拥有完整代码的客户端可以得知JUMP是无效的(由于0x5b是PUSH1的一个操作数)并停止执行。然而,一个接收到块6和块8但没有接收块7的客户端将跳转到位置41,从而以不同的方式对合约进行解析。我们将在后文简要地提及能够避免该问题并支持任意边界的方案。
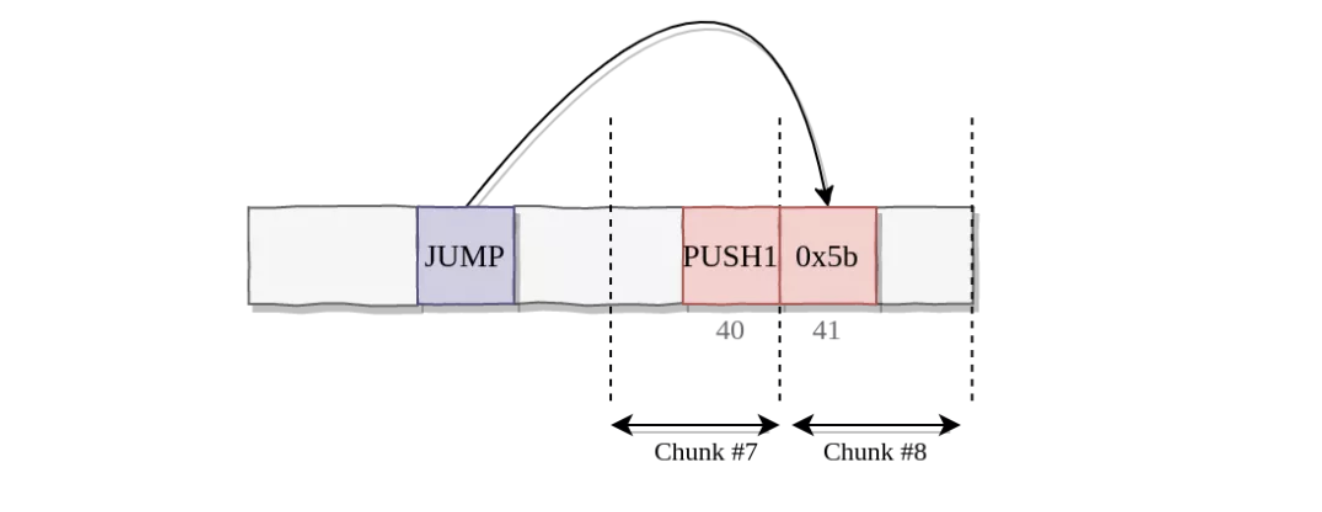
为了解决这个问题,Martin Holst Swende 建议在每个块上添加一个元数据,指定头部的多少个字节为PUSH的操作数。然后,验证程序可以在进行 JUMPDEST 分析期间跳过这些字节。Alexey正探索的另一条路径为禁止EVM中的动态跳转(至少对于希望默克尔化代码的合约而言),让我们能在部署时一次过静态地对跳转进行分析而不是在每次代码执行期间。Alex Beregszaszi 提出使用合约控制流图能够更好地指引默克尔化。同时,Christian Reitweissner 提出一个执行证明方案,其中默克尔化 DAG 是由合约的控制流图所创建。我不能客观地评价他在这篇文章中的思路,同时希望他能够在未来进行更多的说明。
结果或许会表明不同的分割算法在效率上仅有微不足道的提升。在这种情况下,最简单的算法将成为最明智的选择。好消息是,我们至少有一个在早期数据上似乎可以显著地减少无状态区块中传输代码量的算法。
本文特地对 EVM 字节码的默克尔化进行了讨论,但其总体思路并不局限于 EVM。事实上,其它 EWASM 团队正同时对默克尔化 WASM 代码进行实验,其面临着自身的一系列挑战。这主要是因为 WASM 代码由多个部分组成并在执行前有着严格的校验,这意味着重构的字节码必须通过校验。请持续关注这方面的进展。
致谢:非常感谢 EWASM 团队的 Guillaume Ballet,Alex Beregszaszi 和 Casey Detrio 对本文的审阅和反馈。
作者:Sina Mahmoodi
编译:Unitimes_David 翻译: https://mp.weixin.qq.com/s/mPOVoK9Tkt9c_9or5Y85SQ 原文:https://medium.com/ewasm/evm-bytecode-merklization-2a8366ab0c90




