死磕以太坊源码分析之Fetcher同步
- mindcarver
- 发布于 2021-02-21 14:19
- 阅读 2337
死磕以太坊源码分析之Fetcher同步
死磕以太坊源码分析之Fetcher同步
Fetcher 功能概述
区块数据同步分为被动同步和主动同步:
-
被动同步是指本地节点收到其他节点的一些广播的消息,然后请求区块信息。
-
主动同步是指节点主动向其他节点请求区块数据,比如geth刚启动时的syning,以及运行时定时和相邻节点同步
Fetcher负责被动同步,主要做以下事情:
- 收到完整的block广播消息(NewBlockMsg)
- 收到blockhash广播消息(NewBlockHashesMsg)
这两个消息又是分别由 peer.AsyncSendNewBlockHash 和 peer.AsyncSendNewBlock 两个方法发出的,这两个方法只有在矿工挖到新的区块时才会被调用:
// 订阅本地挖到新的区块的消息
func (pm *ProtocolManager) minedBroadcastLoop() {
for obj := range pm.minedBlockSub.Chan() {
if ev, ok := obj.Data.(core.NewMinedBlockEvent); ok {
pm.BroadcastBlock(ev.Block, true) // First propagate block to peers
pm.BroadcastBlock(ev.Block, false) // Only then announce to the rest
}
}
}func (pm *ProtocolManager) BroadcastBlock(block *types.Block, propagate bool) {
......
if propagate {
......
for _, peer := range transfer {
peer.AsyncSendNewBlock(block, td) //发送区块数据
}
}
if pm.blockchain.HasBlock(hash, block.NumberU64()) {
for _, peer := range peers {
peer.AsyncSendNewBlockHash(block) //发送区块哈希
}
}
}所以,当某个矿工产生了新的区块、并将这个新区块广播给其它节点,而其它远程节点收到广播的消息时,才会用到 fetcher 模块去同步这些区块。
fetcher的状态字段
在 Fetcher 内部对区块进行同步时,会被分成如下几个阶段,并且每个阶段都有一个状态字段与之对应,用来记录这个阶段的数据:
Fetcher.announced:此阶段代表节点宣称产生了新的区块(这个新产生的区块不一定是自己产生的,也可能是同步了其它节点新产生的区块),Fetcher对象将相关信息放到Fetcher.announced中,等待下载。Fetcher.fetching:此阶段代表之前「announced」的区块正在被下载。Fetcher.fetched:代表区块的header已下载成功,现在等待下载body。Fetcher.completing:代表body已经发起了下载,正在等待body下载成功。Fetcher.queued:代表body已经下载成功。因此一个区块的数据:header和 body 都已下载完成,此区块正在等待写入本地数据库。
Fetcher 同步区块哈希
而新产生区块时,会使用消息 NewBlockHashesMsg 和 NewBlockMsg 对其进行传播。因此 Fetcher 对象也是从这两个消息处发现新的区块信息的。先来看同步区块哈希的过程。
case msg.Code == NewBlockHashesMsg:
var announces newBlockHashesData
if err := msg.Decode(&announces); err != nil {
return errResp(ErrDecode, "%v: %v", msg, err)
}
// Mark the hashes as present at the remote node
// 将hash 标记存在于远程节点上
for _, block := range announces {
p.MarkBlock(block.Hash)
}
// Schedule all the unknown hashes for retrieval 检索所有未知哈希
unknown := make(newBlockHashesData, 0, len(announces))
for _, block := range announces {
if !pm.blockchain.HasBlock(block.Hash, block.Number) {
unknown = append(unknown, block) // 本地不存在的话就扔到unkonwn里面
}
}
for _, block := range unknown {
pm.fetcher.Notify(p.id, block.Hash, block.Number, time.Now(), p.RequestOneHeader, p.RequestBodies)
}先将接收的哈希标记在远程节点上,然后去本地检索是否有这个哈希,如果本地数据库不存在的话,就放到unknown里面,然后通知本地的fetcher模块再去远程节点上请求此区块的header和body。 接下来进入到fetcher.Notify方法中。
func (f *Fetcher) Notify(peer string, hash common.Hash, number uint64, time time.Time,
headerFetcher headerRequesterFn, bodyFetcher bodyRequesterFn) error {
block := &announce{
hash: hash,
number: number,
time: time,
origin: peer,
fetchHeader: headerFetcher,
fetchBodies: bodyFetcher,
}
select {
case f.notify <- block:
return nil
case <-f.quit:
return errTerminated
}它构造了一个 announce 结构,并将其发送给了 Fetcher.notify 这个 channel。注意 announce 这个结构里带着下载 header 和 body 的方法: fetchHeader 和 fetchBodies 。这两个方法在下面的过程中会讲到。 接下来我们进入到fetcher.go的loop函数中,找到notify,分以下几个内容:
①:校验防止Dos攻击(限制为256个)
count := f.announces[notification.origin] + 1
if count > hashLimit {
log.Debug("Peer exceeded outstanding announces", "peer", notification.origin, "limit", hashLimit)
propAnnounceDOSMeter.Mark(1)
break
}②:新来的块号必须满足 $chainHeight - blockno < 7$ 或者 $blockno - chainHeight < 32$
if notification.number > 0 {
if dist := int64(notification.number) - int64(f.chainHeight()); dist < -maxUncleDist || dist > maxQueueDist {
... }
}③:准备下载header的fetching中存在此哈希则跳过
if _, ok := f.fetching[notification.hash]; ok {
break
}④:准备下载body的completing中存在此哈希也跳过
if _, ok := f.completing[notification.hash]; ok {
break
}⑤:当确定fetching和completing不存在此区块哈希时,则把此区块哈希放入到announced中,准备拉取header和body。
f.announced[notification.hash] = append(f.announced[notification.hash], notification)⑥:如果 Fetcher.announced 中只有刚才新加入的这一个区块哈希,那么调用 Fetcher.rescheduleFetch 重新设置变量 fetchTimer 的周期
if len(f.announced) == 1 {
f.rescheduleFetch(fetchTimer)
}拉取header
接下来就是到fetchTimer.C函数中:进行拉取header的操作了,具体步骤如下:
①:选择要下载的区块,从 announced 转移到 fetching 中
for hash, announces := range f.announced {
if time.Since(announces[0].time) > arriveTimeout-gatherSlack {
// 随机挑一个进行fetching
announce := announces[rand.Intn(len(announces))]
f.forgetHash(hash)
// If the block still didn't arrive, queue for fetching
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.fetching[hash] = announce //
}
}
}②:发送下载 header 的请求
//发送所有的header请求
for peer, hashes := range request {
log.Trace("Fetching scheduled headers", "peer", peer, "list", hashes)
fetchHeader, hashes := f.fetching[hashes[0]].fetchHeader, hashes
go func() {
if f.fetchingHook != nil {
f.fetchingHook(hashes)
}
for _, hash := range hashes {
headerFetchMeter.Mark(1)
fetchHeader(hash)
}
}()
}现在我们再回到f.notify函数中,找到p.RequestOneHeader,发送GetBlockHeadersMsg给远程节点,然后远程节点再通过case msg.Code == GetBlockHeadersMsg进行处理,本地区块链会返回headers,然后再发送回去。
origin = pm.blockchain.GetHeaderByHash(query.Origin.Hash)
...
p.SendBlockHeaders(headers)这时候我们请求的headers被远程节点给发送回来了,又是通过新的消息BlockHeadersMsg来传递的,当请求的 header 到来时,会通过两种方式来过滤header :
Fetcher.FilterHeaders通知Fetcher对象
case msg.Code == BlockHeadersMsg:
....
filter := len(headers) == 1
if filter {
headers = pm.fetcher.FilterHeaders(p.id, headers, time.Now())
}2.downloader.DeliverHeaders 通知downloader对象
if len(headers) > 0 || !filter {
err := pm.downloader.DeliverHeaders(p.id, headers)
...
}downloader相关的放在接下的文章探讨。继续看FilterHeaders:
filter := make(chan *headerFilterTask)
select {
case f.headerFilter <- filter: ①
....
select {
case filter <- &headerFilterTask{peer: peer, headers: headers, time: time}: ②
...
select {
case task := <-filter: ③
return task.headers
...
}主要分为3个步骤:
- 先发一个通信用的
channel给headerFilter - 将要过滤的
headerFilterTask发送给filter - 检索过滤后剩余的标题
主要的处理步骤还是在loop函数中的filter := <-f.headerFilter,在探讨处理前,先了解三个参数的含义:
unknown:未知的headerincomplete:header拉取完成,但是body还没有拉取complete:header和body都拉取完成,一个完整的块,可导入到数据库
接下来正式进入到for _, header := range task.headers {}循环中: 这是第一段重要的循环
①:判断是否是在fetching中的header,并且不是其他同步算法的header
if announce := f.fetching[hash]; announce != nil && announce.origin == task.peer && f.fetched[hash] == nil && f.completing[hash] == nil && f.queued[hash] == nil {
.....
}②:如果传递的header与承诺的number不匹配,删除peer
if header.Number.Uint64() != announce.number {
f.dropPeer(announce.origin)
f.forgetHash(hash)
}③:判断此区块在本地是否已存在,如果不存在且只有header(空块),直接放入complete以及f.completing中,否则就放入到incomplete中等待同步body。
if f.getBlock(hash) == nil {
announce.header = header
announce.time = task.time
if header.TxHash == types.DeriveSha(types.Transactions{}) && header.UncleHash == types.CalcUncleHash([]*types.Header{}) {
...
block := types.NewBlockWithHeader(header)
block.ReceivedAt = task.time
complete = append(complete, block)
f.completing[hash] = announce
continue
}
incomplete = append(incomplete, announce) // 否则添加到需要完成拉取body的列表中④:如果f.fetching中不存在此哈希,就放入到unkown中
else {
// Fetcher doesn't know about it, add to the return list |fetcher 不认识的放到unkown中
unknown = append(unknown, header)
}⑤:之后再把Unknown的header再通知fetcher继续过滤
select {
case filter <- &headerFilterTask{headers: unknown, time: task.time}:
case <-f.quit:
return
}接着就是进入到第二个循环,要准备拿出incomplete里的哈希,进行同步body的同步
for _, announce := range incomplete {
hash := announce.header.Hash()
if _, ok := f.completing[hash]; ok {
continue
}
f.fetched[hash] = append(f.fetched[hash], announce)
if len(f.fetched) == 1 {
f.rescheduleComplete(completeTimer)
}
}如果f.completing中存在,就表明已经在开始同步body了,直接跳过,否则把这个哈希放入到f.fetched,表示header同步完毕,准备body同步,由f.rescheduleComplete(completeTimer)完成。最后是安排只有header的区块进行导入操作.
for _, block := range complete {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}重点分析completeTimer.C,同步body的操作,这步完成就是要准备区块导入到数据库流程了。
拉取body
进入completeTimer.C,从f.fetched获取哈希,如果本地区块链查不到的话就把这个哈希放入到f.completing中,再循环进行fetchBodies,整个流程就结束了,代码大致如下:
case <-completeTimer.C:
...
for hash, announces := range f.fetched {
....
if f.getBlock(hash) == nil {
request[announce.origin] = append(request[announce.origin], hash)
f.completing[hash] = announce
}
}
for peer, hashes := range request {
...
go f.completing[hashes[0]].fetchBodies(hashes)
}
...关键的拉取body函数: p.RequestBodies,发送GetBlockBodiesMsg消息同步body。回到handler里面去查看对应的消息:
case msg.Code == GetBlockBodiesMsg:
// Decode the retrieval message
msgStream := rlp.NewStream(msg.Payload, uint64(msg.Size))
if _, err := msgStream.List(); err != nil {
return err
}
var (
hash common.Hash
bytes int
bodies []rlp.RawValue
)
for bytes < softResponseLimit && len(bodies) < downloader.MaxBlockFetch {
...
if data := pm.blockchain.GetBodyRLP(hash); len(data) != 0 {
bodies = append(bodies, data)
bytes += len(data)
}
}
return p.SendBlockBodiesRLP(bodies)softResponseLimit返回的body大小最大为$2 1024 1024$,MaxBlockFetch表示每个请求最多128个body。
之后直接通过GetBodyRLP返回数据通过SendBlockBodiesRLP发回给节点。
节点将会接收到新消息:BlockBodiesMsg,进入查看:
// 过滤掉filter请求的body 同步,其他的都交给downloader
filter := len(transactions) > 0 || len(uncles) > 0
if filter {
transactions, uncles = pm.fetcher.FilterBodies(p.id, transactions, uncles, time.Now())
}
if len(transactions) > 0 || len(uncles) > 0 || !filter {
err := pm.downloader.DeliverBodies(p.id, transactions, uncles)
...
}过滤掉filter请求的body 同步,其他的都交给downloader,downloader部分之后的篇章讲。进入到FilterBodies:
filter := make(chan *bodyFilterTask)
select {
case f.bodyFilter <- filter: ①
case <-f.quit:
return nil, nil
}
// Request the filtering of the body list
// 请求过滤body 列表
select { ②
case filter <- &bodyFilterTask{peer: peer, transactions: transactions, uncles: uncles, time: time}:
case <-f.quit:
return nil, nil
}
// Retrieve the bodies remaining after filtering
select { ③:
case task := <-filter:
return task.transactions, task.uncles主要分为3个步骤:
- 先发一个通信用的
channel给bodyFilter - 将要过滤的
bodyFilterTask发送给filter - 检索过滤后剩余的
body
现在进入到case filter := <-f.bodyFilter里面,大致做了以下几件事:
①:首先从f.completing中获取要同步body的哈希
for i := 0; i < len(task.transactions) && i < len(task.uncles); i++ {
for hash, announce := range f.completing {
...
}
}②:然后从f.queued去查这个哈希是不是已经获取了body,如果没有并满足条件就创建一个完整block
if f.queued[hash] == nil {
txnHash := types.DeriveSha(types.Transactions(task.transactions[i]))
uncleHash := types.CalcUncleHash(task.uncles[i])
if txnHash == announce.header.TxHash && uncleHash == announce.header.UncleHash && announce.origin == task.peer {
matched = true
if f.getBlock(hash) == nil {
block := types.NewBlockWithHeader(announce.header).WithBody(task.transactions[i], task.uncles[i])
block.ReceivedAt = task.time
blocks = append(blocks, block)
}
}③:最后对完整的块进行导入
for _, block := range blocks {
if announce := f.completing[block.Hash()]; announce != nil {
f.enqueue(announce.origin, block)
}
}最后用一张粗略的图来大概的描述一下整个同步区块哈希的流程:
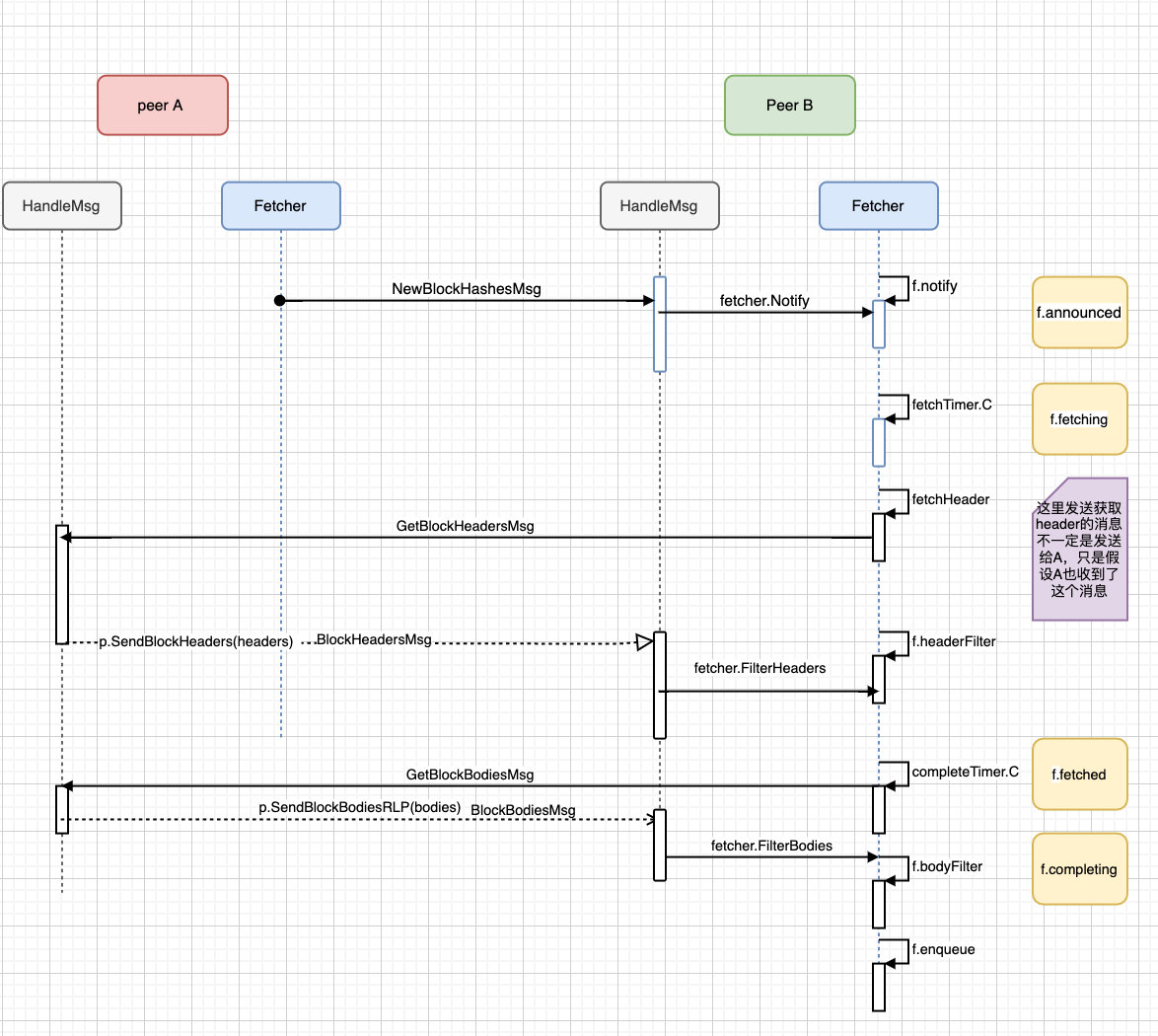
同步区块哈希的最终会走到f.enqueue里面,这个也是同步区块最重要的要做的一件事,下文就会讲到。
Fetcher 同步区块
分析完上面比较复杂的同步区块哈希过程,接下来就要分析比较简单的同步区块过程。从NewBlockMsg开始:
主要做两件事:
①:fetcher模块导入远程节点发过来的区块
pm.fetcher.Enqueue(p.id, request.Block)②:主动同步远程节点
if _, td := p.Head(); trueTD.Cmp(td) > 0 {
p.SetHead(trueHead, trueTD)
currentBlock := pm.blockchain.CurrentBlock()
if trueTD.Cmp(pm.blockchain.GetTd(currentBlock.Hash(), currentBlock.NumberU64())) > 0 {
go pm.synchronise(p)
}
}主动同步由Downloader去处理,我们这篇只讨论fetcher相关。
区块入队列
pm.fetcher.Enqueue(p.id, request.Block)case op := <-f.inject:
propBroadcastInMeter.Mark(1)
f.enqueue(op.origin, op.block)正式进入将区块送进queue中,主要做了以下几件事:
①: 确保新加peer没有导致DOS攻击
count := f.queues[peer] + 1
if count > blockLimit {
log.Debug("Discarded propagated block, exceeded allowance", "peer", peer, "number", block.Number(), "hash", hash, "limit", blockLimit)
propBroadcastDOSMeter.Mark(1)
f.forgetHash(hash)
return
}②:丢弃掉过去的和比较老的区块
if dist := int64(block.NumberU64()) - int64(f.chainHeight()); dist < -maxUncleDist || dist > maxQueueDist {
f.forgetHash(hash)
}③:安排区块导入
if _, ok := f.queued[hash]; !ok {
op := &inject{
origin: peer,
block: block,
}
f.queues[peer] = count
f.queued[hash] = op
f.queue.Push(op, -int64(block.NumberU64()))
if f.queueChangeHook != nil {
f.queueChangeHook(op.block.Hash(), true)
}
log.Debug("Queued propagated block", "peer", peer, "number", block.Number(), "hash", hash, "queued", f.queue.Size())
}到此为止,已经将区块送入到queue中,接下来就是要回到loop函数中去处理queue中的区块。
区块入库
loop函数在处理队列中的区块主要做了以下事情:
- 判断队列是否为空
- 取出区块哈希,并且和本地链进行比较,如果太高的话,就暂时不导入
- 最后通过f.insert将区块插入到数据库。
代码如下:
height := f.chainHeight()
for !f.queue.Empty() {
op := f.queue.PopItem().(*inject)
hash := op.block.Hash()
...
number := op.block.NumberU64()
if number > height+1 {
f.queue.Push(op, -int64(number))
...
break
}
if number+maxUncleDist < height || f.getBlock(hash) != nil {
f.forgetBlock(hash)
continue
}
f.insert(op.origin, op.block) //导入块
}进入到f.insert中,主要做了以下几件事:
①:判断区块的父块是否存在,不存在则中断插入
parent := f.getBlock(block.ParentHash())
if parent == nil {
log.Debug("Unknown parent of propagated block", "peer", peer, "number", block.Number(), "hash", hash, "parent", block.ParentHash())
return
}②: 快速验证header,并在传递时广播该块
switch err := f.verifyHeader(block.Header()); err {
case nil:
propBroadcastOutTimer.UpdateSince(block.ReceivedAt)
go f.broadcastBlock(block, true)③:运行真正的插入逻辑
if _, err := f.insertChain(types.Blocks{block}); err != nil {
log.Debug("Propagated block import failed", "peer", peer, "number", block.Number(), "hash", hash, "err", err)
return
}④:导入成功广播此块
go f.broadcastBlock(block, false)真正做区块入库的是f.insertChain,这里会调用blockchain模块去操作,具体细节会后续文章讲述,到此为止Fether模块的同步就到此结束了,下面是同步区块的流程图:
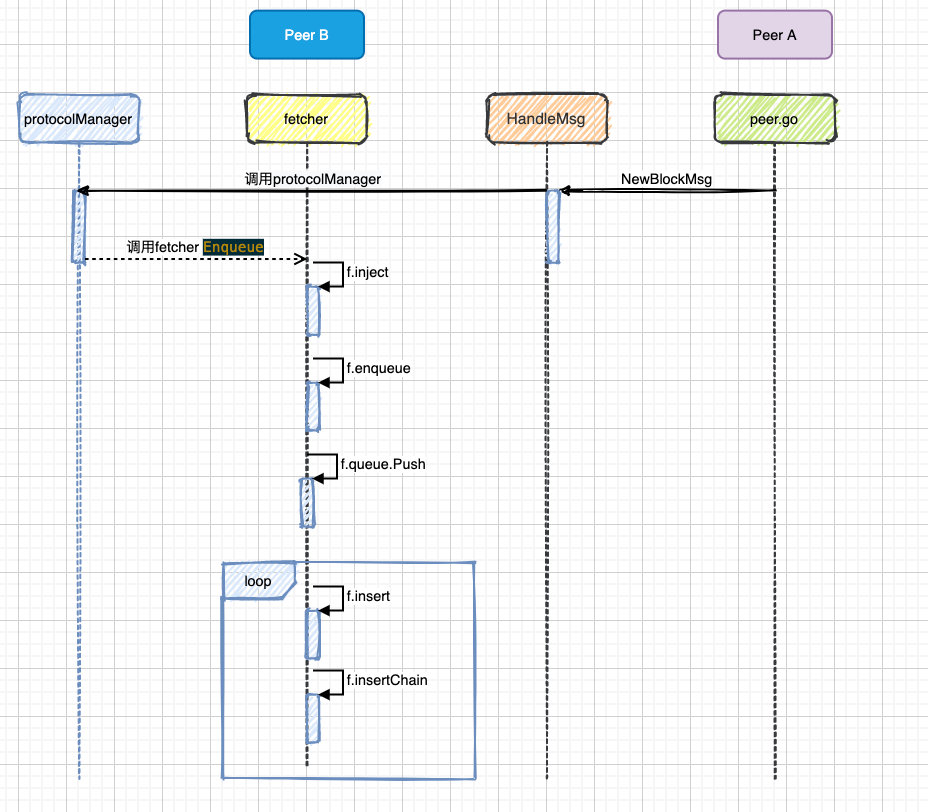
参考
https://github.com/blockchainGuide (文章资料在此,给个Star哦)




