Filecoin - SDR性能优化原理分析
- Star Li
- 发布于 2020-09-28 09:03
- 阅读 1546
Filecoin官方宣布了SDR的优化版本。在AMD3970x上,P1的性能2小时10分钟。优化思路比较清晰,通过预读取base/exp parent的数据,让数据的准备和sha256的计算并行。
Filecoin官方今天正式宣布了SDR的优化版本。在AMD3970x上,P1的性能2小时10分钟。看了看官方的优化思路,分享一下。P1性能优化的核心Patch如下:
commit 0313c663c1b4c7ea891dcaf7245e2cc5eb4b1f81
Author: dignifiedquire
Date: Thu Aug 27 23:08:12 2020 +0200
Optimize Phase1.这个Patch在8月27号就做出来了。优化思路比较清晰:通过预读取base/exp parent的数据,让数据的准备和sha256的计算并行。在介绍具体的优化逻辑之前,介绍一下AMD CPU架构的小知识:
1. Core Complex
CCX是AMD CPU架构的一个术语。CCX - CPU Core Complex。CCX指的是一组(4个)CPU核心和缓存(L1/L2/L3)。4个CCX一组,也有一个专门的术语 - CCD (Core Chiplet Die)。AMD的Ryzen 3000系列的处理器都采用类似的架构。
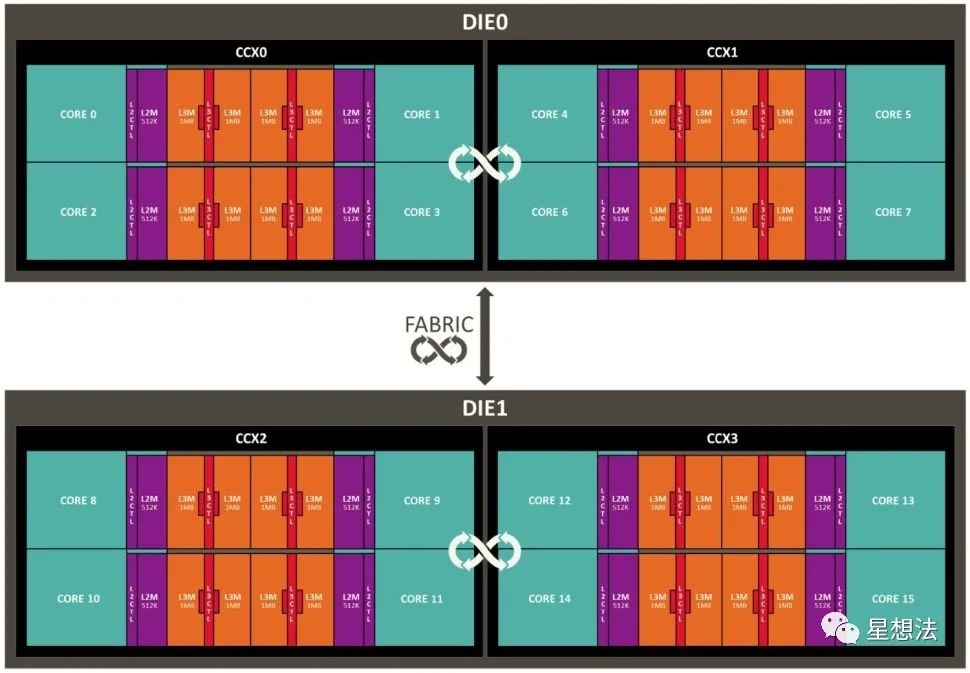
上图给一个示例。整个芯片由两个die组成(上面是die0,下面是die1)。每个Die(CCD)包括两个CCX。注意的是,每个core都有自己的L1/L2缓存,但是L3缓存是几个Core共享的。也就是说,在CCX的四个核可以共享L3缓存,如果四个核需要访问同一段数据,可以加速数据的访问时间。
2. SDR算法优化思路
SDR算法在之前的文章中详细介绍:
优化之前计算一层的某个节点是这样的:
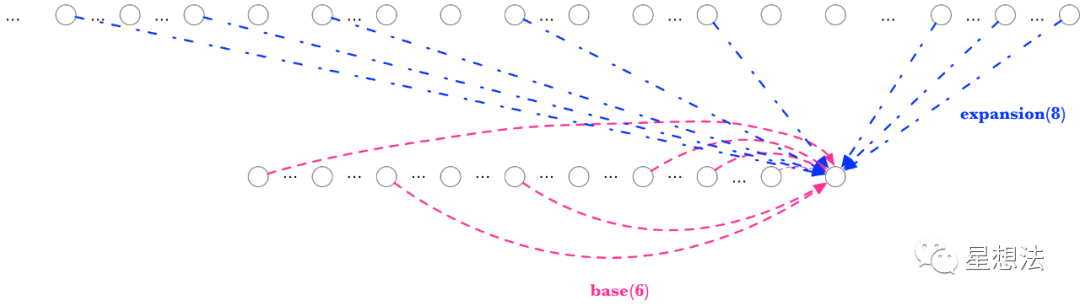
在计算某个节点时,临时获取exp/base的parent节点信息,再进行sha256的计算。
优化后的计算方式如下:
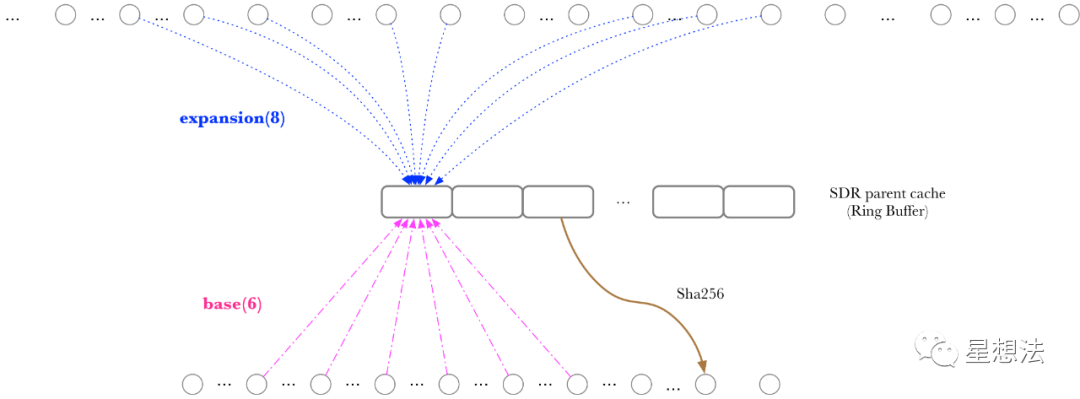
优化的思路,就是将exp/base的parent节点信息的获取和sha256的计算并行。在进行节点计算之前,预先读取exp/base的节点信息并保存在sdr_parent_cache环缓冲中。注意,sdr_parent_cache和parent_cache不一样。sdr_parent_cache是某个节点依赖的多个节点的信息,parent_cache是节点依赖信息的缓存。Filecoin官方称这个优化是Multi-core优化,有几个原因:
- 节点依赖数据的预读取和节点的计算由多核实现。
- 预读取的逻辑本身也是由多核实现。
3. SDR算法优化逻辑分析
明确了优化思路,SDR算法优化的代码还是比较容易理解的。核心逻辑在storage-proofs/porep/src/stacked/vanilla/create_label/mult.rs代码的create_layer_labels函数中。
fn create_layer_labels(
parents_cache: &CacheReader<u32>,
replica_id: &[u8],
layer_labels: &mut MmapMut,
exp_labels: Option<&mut MmapMut>,
num_nodes: u64,
cur_layer: u32,
) -> Result<()> {parents_cache是节点依赖关系的cache数据,replica_id是replia的编号信息,layer_labels和exp_labels分别是当前层和上一层的数据,num_nodes节点个数,cur_layer是当前层的编号。
逻辑的实现采用“生产者/消费者“模式,生产者”生成“节点依赖数据,消费者获取这些数据并进行sha256的计算。
3.1 确定生产者配置
生产者,通过多线程预读取某个节点依赖的节点数据。lookahead指预读取最大的节点个数。num_producers是使用多少个生产者。producer_stride是每个生产者一次生产多少个节点的依赖数据。
let (lookahead, num_producers, producer_stride) = if cur_layer == 1 {
(400, 1, 16)
} else {
(800, 2, 128)
};在Layer为1时,采用1个生产者,每个生产者一次生产16个节点的依赖数据。其他Layer时,采用2个生产者,每个生产者一次生产128个节点的依赖数据。Layer为1和其他时候区分开,是因为Layer1的依赖关系和其他层不一样。
3.2 申请Ring缓存
生产者预生成的节点依赖数据是通过Ring缓存(ring_buf)存储。这个存储在生产者和消费者之间共享。
const BYTES_PER_NODE: usize = (NODE_SIZE * DEGREE) + 64;
let mut ring_buf = RingBuf::new(BYTES_PER_NODE, lookahead);
let mut base_parent_missing = vec![BitMask::default(); lookahead];
// Fill in the fixed portion of all buffers
for buf in ring_buf.iter_slot_mut() {
prepare_block(replica_id, cur_layer, buf);
}需要解释一下base_parent_missing。因为base parent的节点需要当前层前面节点的计算结果,在预读取的时候,可能这些节点还没有计算出来。这些节点的信息通过base_parent_missing标示出来。注意,ring_buf中的每个节点的数据除了依赖的节点信息外,还有一些辅助信息(replica_id, node_id等等)。这些辅助信息的长度是64,所以BYTES_PER_NODE还会加上64。prepare_block函数就是预先填充辅助信息。
3.3 申请原子锁操作
生产者和消费者之间需要同步。多个生产者之间也需要同步。
// Node the consumer is currently working on
let cur_consumer = AtomicU64::new(0);
// Highest node that is ready from the producer
let cur_producer = AtomicU64::new(0);
// Next node to be filled
let cur_awaiting = AtomicU64::new(1);cur_consumer和cur_producer就是用于生产者和消费者之间的同步。cur_awaiting用于多个生产者之间的同步。
3.4 启动生产者
设定了多少生产者,就启动个多少线程。每个线程调用create_label_runner函数,实现了具体的预读取逻辑。
for _i in 0..num_producers {
let layer_labels = &layer_labels;
let exp_labels = exp_labels.as_ref();
let cur_consumer = &cur_consumer;
let cur_producer = &cur_producer;
let cur_awaiting = &cur_awaiting;
let ring_buf = &ring_buf;
let base_parent_missing = &base_parent_missing;
runners.push(s.spawn(move |_| {
create_label_runner(
parents_cache,
layer_labels,
exp_labels,
num_nodes,
cur_consumer,
cur_producer,
cur_awaiting,
producer_stride,
lookahead as u64,
ring_buf,
base_parent_missing,
)
}));
}具体的逻辑比较清晰易懂,感兴趣的小伙伴直接看源代码。
3.5 启动消费者
消费者的逻辑相对多一些。每一层的第一个节点因为没有base parent节点,计算比较特殊,单独处理:
let mut buf = [0u8; (NODE_SIZE * DEGREE) + 64];
prepare_block(replica_id, cur_layer, &mut buf);
cur_node_ptr[..8].copy_from_slice(&SHA256_INITIAL_DIGEST);
compress256!(cur_node_ptr, buf, 2);
// Fix endianess
cur_node_ptr[..8].iter_mut().for_each(|x| *x = x.to_be());
cur_node_ptr[7] &= 0x3FFF_FFFF; // Strip last two bits to ensure in Fr查看生产者提供了多少节点数据,并开始进行处理:
let ready_count = producer_val - i + 1;
for _count in 0..ready_count {
cur_node_ptr = &mut cur_node_ptr[8..];
// Grab the current slot of the ring_buf
let buf = unsafe { ring_buf.slot_mut(cur_slot) };处理过程分为两部分。第一部分,base parent有可能有缺失,先补充缺失的数据:
for k in 0..BASE_DEGREE {
let bpm = unsafe { base_parent_missing.get(cur_slot) };
if bpm.get(k) {
// info!("getting missing parent, k={}", k);
let source = unsafe {
if cur_parent_ptr.is_empty() {
cur_parent_ptr =
parents_cache.consumer_slice_at(cur_parent_ptr_offset);
}
// info!("after unsafe, when getting miss parent");
let start = cur_parent_ptr[0] as usize * NODE_WORDS;
let end = start + NODE_WORDS;
// info!("before as_slice(), when getting miss parent");
&layer_labels.as_slice()[start..end]
};
buf[64 + (NODE_SIZE * k)..64 + (NODE_SIZE * (k + 1))]
.copy_from_slice(source.as_byte_slice());
// info!("got missing parent, k={}", k);
}
cur_parent_ptr = &cur_parent_ptr[1..];
cur_parent_ptr_offset += 1;
}第二部分,在base parent数据补充完整后,所有的数据都已经准备完成,进行sha256的计算:
if cur_layer == 1 {
// Six rounds of all base parents
for _j in 0..6 {
compress256!(cur_node_ptr, &buf[64..], 3);
}
// round 7 is only first parent
memset(&mut buf[96..128], 0); // Zero out upper half of last block
buf[96] = 0x80; // Padding
buf[126] = 0x27; // Length (0x2700 = 9984 bits -> 1248 bytes)
compress256!(cur_node_ptr, &buf[64..], 1);
} else {
// Two rounds of all parents
let blocks = [
*GenericArray::::from_slice(&buf[64..128]),
*GenericArray::::from_slice(&buf[128..192]),
*GenericArray::::from_slice(&buf[192..256]),
*GenericArray::::from_slice(&buf[256..320]),
*GenericArray::::from_slice(&buf[320..384]),
*GenericArray::::from_slice(&buf[384..448]),
*GenericArray::::from_slice(&buf[448..512]),
];
sha2::compress256((&mut cur_node_ptr[..8]).try_into().unwrap(), &blocks);
sha2::compress256((&mut cur_node_ptr[..8]).try_into().unwrap(), &blocks);
// Final round is only nine parents
memset(&mut buf[352..384], 0); // Zero out upper half of last block
buf[352] = 0x80; // Padding
buf[382] = 0x27; // Length (0x2700 = 9984 bits -> 1248 bytes)
compress256!(cur_node_ptr, &buf[64..], 5);
}计算分为两种情况,一种是第一层的数据,一种是其他层的数据。计算sha256的过程稍稍有些不同。至此,整个优化算法逻辑就完整了。
总结:
Filecoin官方宣布了SDR的优化版本。在AMD3970x上,P1的性能2小时10分钟。优化思路比较清晰,通过预读取base/exp parent的数据,让数据的准备和sha256的计算并行。





