一文了解数据和API如何驱动未来经济
- Chainlink
- 发布于 2020-07-20 11:26
- 阅读 902
区块链上的智能合约就像未连接互联网的计算机一样,本身就具有其内在价值,智能合约的内在价值就是创建和交易通证。然而,计算机连接了互联网后,释放出了巨大的创新力和价值,同样地,智能合约一旦连接到快速增长的链下数据和API经济,也将变得无比强大。
在前两篇科普系列文章中,我们讨论了区块链和智能合约如何作为新一代基础架构安全可靠地转移和储存价值。区块链上的智能合约就像未连接互联网的计算机一样,本身就具有其内在价值,智能合约的内在价值就是创建和交易通证。然而,计算机连接了互联网后,释放出了巨大的创新力和价值,同样地,智能合约一旦连接到快速增长的链下数据和API经济,也将变得无比强大。如果智能合约可以连接至链下数据提供商、web API、企业系统、云服务商、物联网设备、支付系统以及其他区块链等各种庞大的数据库,那么它将成为横跨各个行业的主流数字协议。本文中,我们将在以下几个方面深度解析数据和API:
-
数据是什么?它如何驱动数据经济?
-
数据是如何被生产出来的?
-
如何通过API交换数据?
-
什么是大数据分析?
本文将全面分析链下数据经济格局,下一篇文章中我们会接着探讨如何使用一种叫“预言机”的基础架构安全可靠地将智能合约连接至这些链下数据。o:p
数据与数据经济
数据
数据是通过观察得出的结果或信息,比如测量室外温度、计算汽车的地理位置或记录用户与应用的交互情况。原始数据本身既不具有特殊价值也不可靠,而是需要用其他数据对其进行解读或确认,以确保数据的真实性和有效性。
元数据
元数据是“关于数据的数据”。元数据中主要包含数据的基本信息,目的是大幅降低追踪和处理信息的难度。举个例子,某个消息的发送时间、某一温度数值的地理位置或某次电话沟通的时长,这些全都是元数据。其目的是为数据建立索引并赋予意义。
数据清洗
除此之外,重要的应用需要保障数据可靠性,因此需要对其进行处理和清洗。这个清洗过程包括去除异常值、发现错误并剔除不相关的信息。比如,将目前温度与历史温度进行比较,以甄别并剔除异常值。
数据经济
在数据经济中,各种类型的数据都会被搜集、提炼和交换,并产生有价值的洞察。这些洞察会产生最大的社会效益,比如在共享医疗数据库中储存临床研究数据,以便大家更好地了解最新医疗趋势;或私营企业追踪内部运营流程,以甄别并改善效率低下问题。
随着数据经济的不断发展,自动化程度也在不断上升。数据可以直接触发经济行为,而无须人为干预。举个例子,应用的算法规定只要满足三个条件,就会自动支付货款,这三个条件分别是:1)货物送达(GPS数据);2)货物品相完好(物联网数据);3)货物已清关(web API)。
数据生产
数据是某一流程或事件的副产品,数据的产生需要输入(即行为)、数据的记录需要提取(即测量)、而为数据赋予意义则需要聚合(即分析)。由于数据的输入、提取和聚合技术存在一定限制门槛,因此数据并不能做到“人人平等”,数据质量也是参差不齐的。
以下是获取新数据和原始数据的常见方式:
-
表格(手动输入的数据):用户填写公开和私人表格(比如回答问卷调查、签署文档或在社交平台发言),手动输入的数据。
-
应用/网站(经过用户同意的数据):在用户同意应用或网站的条款和协议后获取的数据。用户通常在同意这些条款和协议后,就会授权网站或应用追踪某些数据,比如APP中的操作、浏览习惯或甚至是性别和年龄等个人信息。
-
物联网(实时监测的数据):安装了传感器和执行器的设备捕捉到的数据。并通过智能手机、智能家居、可穿戴式设备、射频识别装置等各种互联网设备传输数据。
-
自有流程/个人经验(由内部或个人拥有的数据):企业由于拥有专利或市场领导地位而掌控了某一业务流程,从而获取到的数据;抑或是在个人独特的经验中产生的数据。
-
研究和分析(聚合并诠释数据):搜集来自现有数据集的数据,并对数据进行分析,包括与历史数据进行交叉对比、对其他数据集进行交叉参考以及采用新的过滤和计算方法等。另外还有数据分销商,他们从数据聚合商或企业大量收购数据,然后转卖给终端用户。数据分销商虽然以更高的价格将数据转卖出去,但是他们在转卖之前会按照用户的需求将数据处理成适合的结构或格式。
数据交换
如果数据要成为下一代应用的核心支柱,那么就不能完全依赖内部产生数据,而是必须建立一个数据交易机制,因为买数据的成本比生产数据的成本低多了。举个例子,开发自动驾驶汽车的算法需要运用大量数据进行目标检测、目标分类、目标定位以及运动预测。开发者可以在内部产生这些数据,但代价是需要累计几百万英里的驾驶里程;而他们也可以通过API购买这些数据。
应用程序编程接口(API)其实是一组命令,控制外部应用如何接入系统内部的数据集和服务。API是目前数据和服务交易的标准方案。主流的打车软件Uber连接了MapBox的GPS API进行车辆定位、Twilio的短信息API发送即时消息以及Braintree的支付API进行付款。这些功能都是购买的已有技术方案,而非Uber自己从零开发。
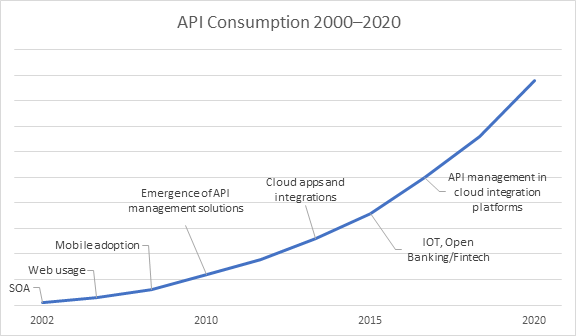
(API经济自出现以来一直呈稳定上升趋势,自此期间产生了许多新的API和管理API的新方案。资料来源:Software Development Company Informatica)
API的收费模式通常是订阅模式,终端用户可以按使用次数付费,也可以按月付费,还可以按照某种阶梯制度付费。因此,数据提供商会得到经济激励生产数据,而终端用户无须自行生产这些数据。API提供方和付费用户之间还会签署具有法律效力的合约,以避免数据盗用或未经许可转卖等各种恶意行为,并约束数据提供商为自己的数据质量负责。
有许多API可免费供所有人使用,其中包括提供天气数据的Open Weather Map、提供航班信息的Skyscanner Flight Search以及提供全球人类行为和信仰数据的GDELT。除此之外,全世界各国政府也积极推出透明数据的倡议,并不断加大力度将API开源。然而,开源API的可靠性还是不如付费API,因为缺少经济激励和法律协议的约束,没法控制数据质量和延时风险。大多数优质数据仍然来自付费API,这些API通常拥有顶尖的数据源、全栈基础架构以及全职的监控团队,并为了超越竞争对手而不断努力创新。
大数据基础架构和分析
编程系统能够自主学习和自我完善,这个概念一直都受到热烈追捧。学习的过程包括采取行动、收到结果、与历史数据比对分析并产生新洞察,改进方法,最终实现目标。因此,目前的大趋势是开发出一个可以自主学习的基础架构,吸取大量数据、对数据进行过滤分类,并基于分析结果产生洞察。
美国的Facebook、Google和亚马逊以及中国的阿里巴巴、腾讯和百度之所以能成为今天的科技巨头,就是因为它们深耕互联网应用,并产生了海量的用户数据。这些数据为世界顶尖的数据分析工具,特别是人工智能和机器学习软件,奠定了坚实的基础。这些大数据分析技术能够针对消费者行为、社会趋势和市场趋势产生大量丰富的洞察。与此同时,业务管理软件也帮助企业更好地了解它们的运营情况。SAP、Salesforce和甲骨文等企业开发了企业资源规划系统(ERP)、客户关系管理系统(CRM)以及云端管理软件,使企业能够汇总内部业务流程中的所有数据和系统,并产生关键洞察。
云端计算和储存技术正受到越来越多的关注。有了云计算,用户可以共享云端基础架构储存和处理数据,从而无须占用自己的系统资源。云技术改善了应用的后端流程,增强了不同系统之间的共享,并降低了人工智能和机器学习软件的使用成本。举个例子,Google Cloud用户可以使用BigQuery,这是一个SaaS软件,可以批量分析千万亿字节的数据,并内置机器学习功能。
第四次工业革命即将到来
将人工智能/机器学习、业务管理软件以及云端基础架构相结合,能从数据中获得更加深刻的洞察。另外,边缘计算、5G通讯网络以及生物科技等技术的兴起也促进了实时数据和生物连接数据环境的发展。在这些新兴系统的推动下,经济体系不断朝着去人为干预和实时数据驱动决策的方向发展,而数据生成和分享的壁垒几乎消失,频率不断上升,这也进一步推动了大趋势的发展。许多人将这个大趋势称为“第四次工业革命”。
欢迎加入 Chainlink 开发者社区
了解更多内容请期待我们之后发布的文章。本科普系列中的下一篇文章将探讨智能合约的话题。欢迎关注我们的 Twitter 账号,收到文章更新通知。还可加入我们的电报群,了解 Chainlink 最新资讯。





