详解实用拜占庭协议PBFT
- 清源
- 发布于 2019-08-29 20:41
- 阅读 16275
PBFT算法和 Raft算法解决的核心问题都是在分布式环境下如何保持集群状态的一致性,简而言之就是一组服务,给定一组操作,最后得到一致的结果。
PBFT算法和 Raft算法解决的核心问题都是在分布式环境下如何保持集群状态的一致性,简而言之就是一组服务,给定一组操作,最后得到一致的结果。
PBFT算法假设的环境又比Raft算法更加的’恶劣‘,Raft算法只支持容错故障节点,而PBFT算法除了需要支持容错故障节点之外,还需要容忍作恶节点。
作恶节点节点是指可能对接收到的消息作出截然相反的回复,甚至伪造消息。
PBFT算法中节点只有两种角色,主节点(primary)和副本(replica),两种角色之间可以相互转换。两者之间的转换又引入了视图(view)的概念,视图在PBFT算法中起到逻辑时钟的作用。
为了更多的容错性,PBFT算法最大的容错节点数量( n - 1 ) / 3,也就是是说4个节点的集群最多只能容忍一个节点作恶或者故障。而Raft算法的最大容错节点是( n - 1) / 2,5个节点的集群可以容忍2个节点故障。
为什么PBFT算法只能容忍(n-1)/3个作恶节点?
节点总数是n,其中作恶节点有f,那么剩下的正确节点为n - f,意味着只要收到n - f个消息就能做出决定,但是这n - f个消息有可能由f个是由作恶节点冒充的,那么正确的消息就是n - f - f个,为了多数一致,正确消息必须占多数,也就是n - f - f > f,但是节点必须是整数个,所以n最少是3f+1个。
或者可以这样理解,假定f个节点是故障节点,f个节点是作恶,那么达成一致需要的正确节点最少就是f+1个,当然这是最坏的情况,如果故障节点集合和拜占庭节点集合有重复,可以不需要f+1个正确节点,但是为了保证最坏的情况算法还能正常运行,所以必须保证正确节点数量是f+1个。
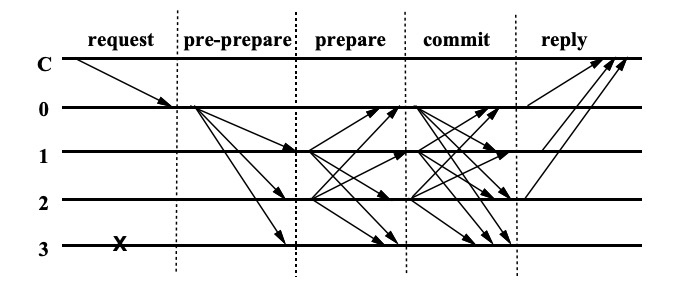
算法流程
在算法开始阶段,主节点由 p = v mod n计算得出,随着v的增长可以看到p不断变化,论文里目前还是轮流坐庄的方法,这里是一个优化点。
首先客户端发送消息m给主节点p,主节点就开始了PBFT三阶段协议,三个阶段分别是预准备(pre-prepare),准备(prepare),提交(commit)。
其中pre-prepare和prepare阶段最重要的任务是保证,同一个主节点发出的请求在同一个视图(view)中的顺序是一致的,prepare和commit阶段最重要的任务是保证请求在不同视图之间的顺序是一致的。
-
主节点收到客户端发送来的消息后,构造
pre-prepare消息结构体< <PRE-PREPARE, v, n, d>, m >广播到集群中的其它节点。PRE-PREPARE标识当前消息所处的协议阶段。v标识当前视图编号。n为主节点广播消息的一个唯一递增序号。d为m的消息摘要。m为客户端发来的消息。
-
副本(backup)收到主节点请求后,会对消息进行检查,检查通过会存储在本节点。当节点收到2f+1(包括自己)个相同的消息后,会进入PREPARE状态,广播消息< <PREPARA, v, n, d, i> >,其中i是本节点的编号。对消息的有效性有如下检查:- 检查收到的消息体中摘要
d,是否和自己对m生成的摘要一致,确保消息的完整性。 - 检查
v是否和当前视图v一致。 - 检查序号
n是否在水线h和H之间,避免快速消耗可用序号。 - 检查之前是否接收过相同序号
n和v,但是不同摘要d的消息。
- 检查收到的消息体中摘要
-
副本收到2f+1(包括自己)个一致的PREPARE消息后,会进入COMMIT阶段,并且广播消息< COMMIT, v, n, D(m), i >给集群中的其它节点。在收到PREPARE消息后,副本同样也会对消息进行有效性检查,检查的内容是上文1, 2, 3。 -
副本收到2f+1(包括自己)个一致的COMMIT个消息后执行m中包含的操作,其中,如果有多个m则按照序号n从小到大执行,执行完毕后发送执行成功的消息给客户端。
下面就是算法的流程图:
日志压缩
Pbft算法在运行的过程中,日志会不断累积的,但是在实际的系统中,无论是从日志占用的磁盘空间,还是新节点加入集群,同步日志的网络消耗来看,日志都不能无限的增长。
Pbft采用检查点(checkpoint)机制来压缩日志,其本质和Raft算法采用快照的形式清理日志是一样的,只是实现的方式不同。
为每一次操作创建一个集群中稳定检查点,代价是非常昂贵的,Pbft为常数个操作创建一次稳定检查点,比如每100个操作创建一次检查点,而这个检查点就是checkpoint,当这个checkpoint得到集群中多数节点认可以后,就变成了稳定检查点stable checkpoint。
当节点i生成checkpoint后会广播消息<CHECKPOINT, n, d, i>其中n是最后一次执行的消息序号,d是n执行后的状态机状态的摘要。每个节点收到2f+1个相同n和d的checkpoint消息以后,checkpoint就变成了stable checkpoint。同时删除本地序号小于等于n的消息。
同时checkpoint还有一个提高水线(water mark)的作用,当一个stable checkpoint被创建的时候,水线h被修改为stable checkpoint的n,水线H为h + k而k就是之前用到创建checkpoint的那个常数。
视图切换(View-Change)
在正常流程中,可以看到所有客户端发来的消息m都是由主节点p广播到集群的,但是当主节点突然宕机,又怎么保证集群的可用性呢?
view-change提供了一种当主节点宕机以后依然可以保证集群可用性的机制。view-change通过计时器来进行切换,避免副本长时间的等待请求。
当副本收到请求时,就启动一个计时器,如果这个时候刚好有定时器在运行就重置(reset)定时器,但是主节点宕机的时候,副本i就会在当前视图v中超时,这个时候副本i就会触发view-change的操作,将视图切换为v+1。
- 副本
i会停止接收除了checkpoint,view-change和new view-change以外的请求,同时广播消息<VIEW-CHANGE, v+1, n, C, P, i>的消息到集群。n是节点i知道的最后一个stable checkpoint的消息序号。C是节点i保存的经过2f+1个节点确认stable checkpoint消息的集合。P是一个保存了n之后所有已经达到prepared状态消息的集合。
- 当在视图( v+1 )中的主节点
p1接收到2f个有效的将视图变更为v+1的消息以后,p1就会广播一条消息<NEW-VIEW, v+1, V, Q>V是p1收到的,包括自己发送的view-change的消息集合。Q是PRE-PREPARE状态的消息集合,但是这个PRE-PREPARE消息是从PREPARE状态的消息转换过来的。
- 从节点接收到
NEW-VIEW消息后,校验签名,V和Q中的消息是否合法,验证通过,主节点和副本都 进入视图v+1。
当p1在接收到2f+1个VIEW-CHANGE消息以后,可以确定stable checkpoint之前的消息在视图切换的过程中不会丢,但是当前检查点之后,下一个检查点之前的已经PREPARE可能会被丢弃,在视图切换到v+1后,Pbft会把旧视图中已经PREPARE的消息变为PRE-PREPARE然后新广播。
- 如果集合
P为空,广播<PRE-PREPARE, v+1, n, null>,接收节点就什么也不做。 - 如果集合
P不为空,广播<PRE-PREPARE, v+1, n,d>
总结一下,在view-change中最为重要的就是C,P,Q三个消息的集合,C确保了视图变更的时候,stable checkpoint之前的状态安全。P确保了视图变更前,已经PREPARE的消息的安全。Q确保了视图变更后P集合中的消息安全。回想一下pre-prepare和prepare阶段最重要的任务是保证,同一个主节点发出的请求在同一个视图(view)中的顺序是一致的,而在视图切换过程中的C,P,Q三个集合就是解决这个问题的。
主动恢复
集群在运行过程中,可能出现网络抖动、磁盘故障等原因,会导致部分节点的执行速度落后大多数节点,而传统的PBFT拜占庭共识算法并没有实现主动恢复的功能,因此需要添加主动恢复的功能才能参与后续的共识流程,主动恢复会索取网络中其他节点的视图,最新的区块高度等信息,更新自身的状态,最终与网络中其他节点的数据保持一致。
在Raft中采用的方式是主节点记录每个跟随者提交的日志编号,发送心跳包时携带额外信息的方式来保持同步,在Pbft中采用了视图协商(NegotiateView)的机制来保持同步。
一个节点落后太多,这个时候它收到主节点发来的消息时,对消息水线(water mark)的检查会失败,这个时候计时器超时,发送view-change的消息,但是由于只有自己发起view-change达不到2f+1个节点的数量,本来正常运行的节点就退化为一个拜占庭节点,尽管是非主观的原因,为了尽可能保证集群的稳定性,所以加入了视图协商(NegotiateView)机制。
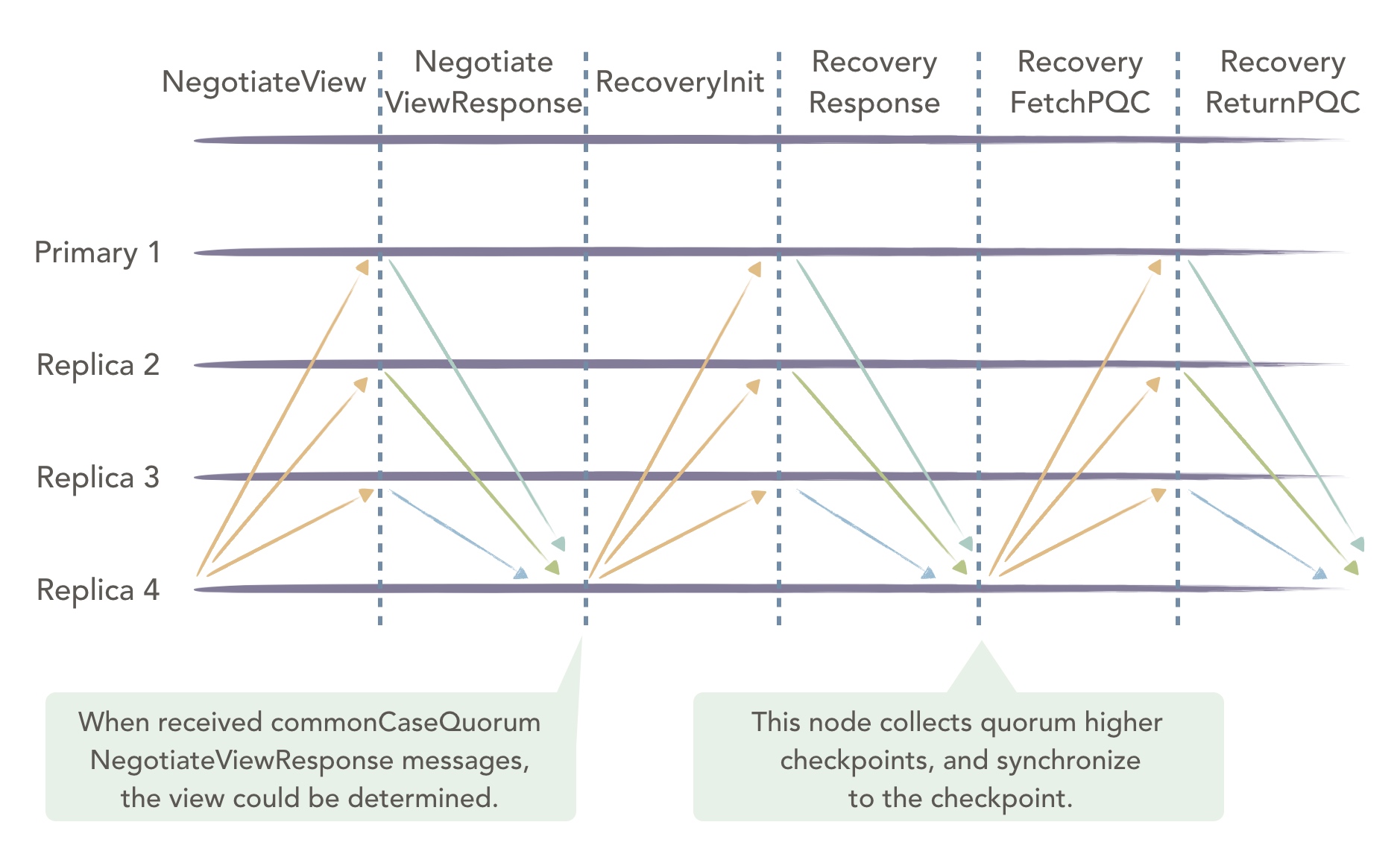
当一个节点多次view-change失败就触发NegotiateView同步集群数据,流程如下;
- 新增节点
Replica 4发起NegotiateView消息给其他节点; - 其余节点收到消息以后,返回自己的视图信息,节点ID,节点总数N;
Replica 4收到2f+1个相同的消息后,如果quorum个视图编号和自己不同,则同步view和N;Replica 4同步完视图后,发送RevoeryToCheckpoint的消息,其中包含自身的checkpoint信息;- 其余节点收到
RevoeryToCheckpoint后将自身最新的检查点信息返回给Replica 4; Replica 4收到quorum个消息后,更新自己的检查点到最新,更新完成以后向正常节点索要pset、qset和cset的信息(即PBFT算法中pre-prepare阶段、prepare阶段和commit阶段的数据)同步至全网最新状态;
增删节点
Replica 5新节点加入的流程如下图所示;
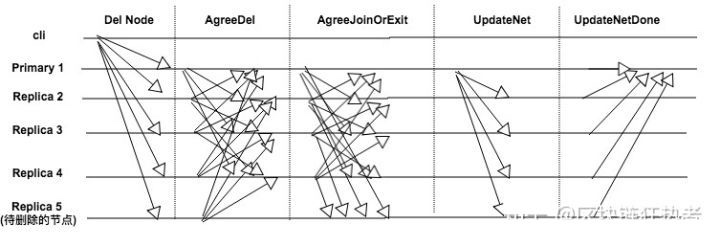
- 新节点启动以后,向网络中其他节点建立连接并且发送
AddNode消息; - 当集群中的节点收到
AddNode消息后,会广播AgreeAdd的消息; - 当一个节点收到
2f+1个AgreeAdd的消息后,会发送AgreeAdd的消息给Replica 5 Replica 5会从收到的消息中,挑选一个节点同步数据,具体的过程在主动恢复中有说明,同步完成以后发送JoinNet- 当集群中其他节点收到
JoinNet之后重新计算视图view,节点总数N,同时将PQC信息封装到AgreeJoinOrExit中广播 - 当收到
2f+1个有效的AgreeJoinOrExit后,新的主节点广播UpdateNet消息完成新增节点流程
删除节点的流程和新增节点的过程类似:
Q&A
Q:为什么PBFT算法需要三个阶段?
A:假如简化为两个阶段pre-prepare和prepare,当一个节点A收到2f+1个相同的prepare后执行请求,一部分节点B发生view-change,在view-change的过程中是拒收prepare消息的,所以这一部分节点的状态机会少执行一个请求,当view-change切换成功后重放prepare消息,在重放的过程中,节点A也完成了view-change,这个时候A就会面临重放的prepare已经执行过了,是否需要再次执行?会导致状态机出现二义性。
Q:view-change阶段集群会不可用么? A:view-change阶段集群会出现短暂的不可用,一般在实践的时候都会实现一个缓冲区来减少影响,实现参考 以太坊TXpool分析。
Q:Pbft算法的时间复杂度?
A:Pbft算法的时间复杂度O(n^2),在prepare和commit阶段会将消息广播两次,一般而言,Pbft集群中的节点都不会超过100。
本文作者是深入浅出区块链共建者清源,欢迎关注清源的博客,不定期分享一些区块链底层技术文章。




