深入理解 Bucket Tree
- 清源
- 发布于 2019-04-24 20:41
- 阅读 6143
Bucket Tree结合了默克尔树和哈希表的特点,如果想要深入了解Bucket Tree就必须掌握默克尔树和哈希表。
Merkle Tree大多用来进行对比验证处理,特别是在分布式环境下进行比对或验证的时候可以大大减少数据传输量和计算的复杂度。
Bucket Tree结合了默克尔树和哈希表的特点,如果想要深入了解Bucket Tree就必须掌握默克尔树和哈希表。
Merkle Tree大多用来进行对比验证处理,特别是在分布式环境下进行比对或验证的时候可以大大减少数据传输量和计算的复杂度。
Merkle(默克尔)树结构解析
Merkle 树特点
- 默克尔树是一种树,一般是二叉树,也可以是多叉树;
- 默克尔树的叶子节点可以是数据项,也可以是数据项的哈希值;
- 非叶子节点的数据项是由其叶子节点Hash计算得到的;
Merkle 树原理
默克尔树是自底向上构建的,下面就是一颗典型的默克尔树。
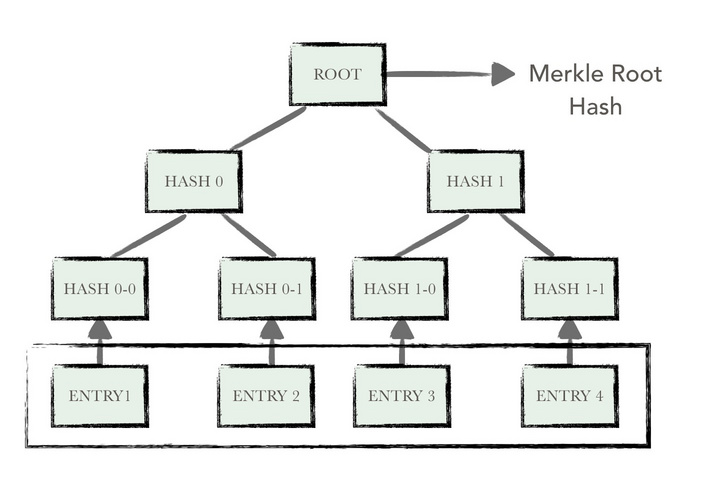
首先计算ENTRY1-ENTRY4单元的数据哈希,然后分别存入到对应的叶子节点,这些叶子节点分别是HASH0-0,HASH0-1,HASH1-0,HASH1-1。
接着将相邻节点的哈希值合并成一个字符串,然后计算这个字符串的哈希值,得到的就是这两个节点父节点的哈希值。
如果用公式表示的话就是这样:
HASH 0 = Hash(HASH 0-0 + HASH 0-1)如果树节点的个数是单数,就对它直接进行哈希运算,或者复制一次这个节点的哈希值,凑齐偶数个节点。
重复上述过程,自底向上就可以构建整个默克尔树了。
Tips:
若两颗树的根哈希一直,则这两棵树的结构,节点内容必然相同。默克尔树的优势
当一个节点内容发生变化的时候,仅需要计算从该节点到根路径上所有节点节点的哈希,减少计算量,同时也方便快速定位数据发生变化的位置。
哈希表
哈希表也称散列表,根据键(key)快速定位值(value)的存储位置的数据结构。
Bucket Tree
Bucket Tree拓展了哈希表的概念,引入了一个桶(bucket),也就是哈希桶。
其结构如下图所示:
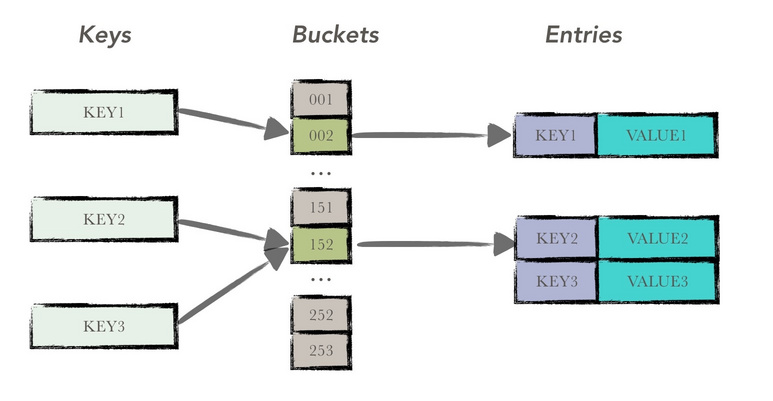
KEY2和KEY3映射到相同的152号桶里。
Bucket tree在扩展哈希表的同时,又在哈希表上建立了默克尔树。
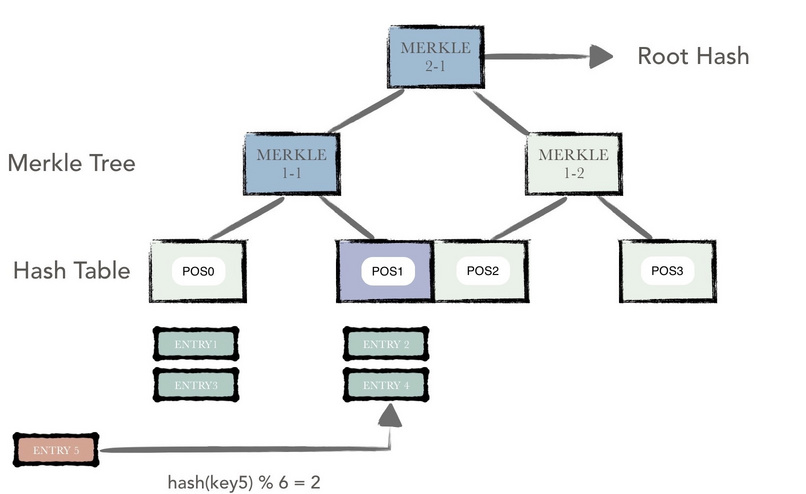
哈希表由一系列的哈希桶(bucket)组成,每个桶中存储着若干被散列到该桶中的数据项(entry)所以数据项按序排列,每一个哈希桶有一个哈希值来标识整个桶,该哈希值是桶内所有数据通过哈希计算所得。
除了底层的哈希表外,上层是一系列的默克尔树节点,一个默克尔树节点对应着下层的N个哈希桶或者默克尔树节点,这个N也称作默克尔树的聚合度。
Bucket Tree 设计目的:
- 利用默克尔树的特点,使每次树状态改变,重新计算哈希的代价最小;
- 利用哈希表进行底层数据的维护,使得数据项均匀分布;
例如上图中,一条新的数据项entry5插入,该数据项被散列到POS为1的桶中。该桶,即从该桶至根节点上所有的节点被标为粉红色,即为脏节点。仅对这些脏节点进行哈希重计算,便可得到一个新的哈希值用来代表新的树状态。
由于bucket tree是一棵固定大小的树(即底层的哈希表容量在树初始化之后,就无法更改了),随着数据量的增大,采用散列函数将所有的数据项进行均匀散列可以避免数据聚集的情况发生。
Bucket tree有两个重要的可调参数
- capacity:表示哈希表的容量,该值越大,整课树所能容纳的数据项个数就越多,在聚合程度不变的前提下,树越高,从叶子节点到根节点的路径越长,哈希计算次数也越多。
- aggreation:表示一个父节点对应的孩子节点的个数,该值越大,表示树的收敛速度越快,在哈希表容量不变的前提下,树更低,从叶子节点到根节点路径越短,哈希计算次数也越少。但是每个默克尔树节点的size就越大,增加磁盘IO开销。
Tips:
- 当有比较多数据变更的时候,非常容易散列到不同bucket,这个时候可以并行计算新bucket的哈希值,加速构建默克尔树。
- 如果Bucket tree树比较大,并且用数据库来存储的话,加上读cache可以显著的提升性能。
本文作者清源,欢迎关注清源的博客,不定期分享一些区块链底层技术文章。
- 学分: 20
- 分类: 入门/理论
- 标签: Bucket Tree Merkle树




